
速递|AI数据标注"腰部玩家"浮出水面?求职网Handshake转型后ARR近10亿美元
速递|AI数据标注"腰部玩家"浮出水面?求职网Handshake转型后ARR近10亿美元AI 公司对更多数据的贪婪需求推高了从事该行业不起眼工作的初创公司的销售额:这些公司与律师、博士学位持有者和医生签约 ,由他们对 AI 模型生成的答案进行评分。
来自主题: AI资讯
7104 点击 2026-04-16 16:08
 搜索
搜索
AI 公司对更多数据的贪婪需求推高了从事该行业不起眼工作的初创公司的销售额:这些公司与律师、博士学位持有者和医生签约 ,由他们对 AI 模型生成的答案进行评分。
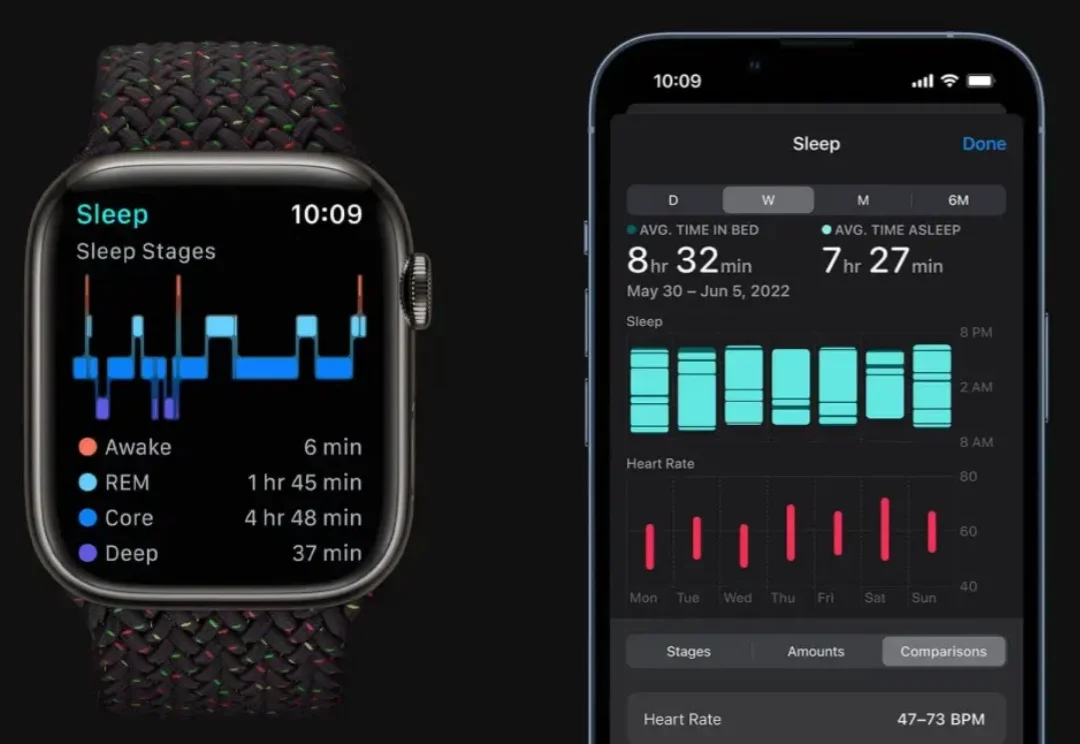
通过一晚上的睡眠,AI 模型就能监控最多 130 种疾病。

3月12日(周四),《纽约时报》发布了最新进展:“牛油果”(Avocado)模型确定再次推迟发布。据知情人士透露,Meta 继续开发数月的全新“前沿级”AI 模型,在推理、编程和写作的内部测试中,表现不及 Google、OpenAI 和 Anthropic 等竞争对手的领先模型。

昨天,我们报道了「OpenAI 光速滑跪,背刺 Anthropic,高调签下军方大单」的新闻。今天,这一事件又有了新进展 ——OpenAI 公布了他们与五角大楼协议的部分内容,声称签的合同能够确保他们的 AI 模型不被用于大规模监控美国公民和自动化武器,和 Anthropic 之前提供的方案「很不一样」。

全球最大游戏博主 PewDiePie,又整活了。他靠着「偷师」DeepSeek、清华大学发布的技术文档,用一堆魔改显卡成功微调出一个自己的 AI 模型,而这个模型在编程基准测试中的表现,竟然超越了 GPT-4 和 Gemini 2.5 Pro。

今天,Web 开发社区爆发了一条令人咋舌的技术新闻。Cloudflare 的一名工程师在一周之内,借助 AI 模型从头重建了 Next.js 。该公司的首席技术官 Dane Knecht 发推庆祝这一史诗级的成就,称之为「Next.js 的解放日」,Next.js 属于每个人。

奥特曼又又又又口出狂言了。在印度 Express Adda 的论坛上,Sam Altman 聊了很多 AI 话题,从 AGI 到中美 AI 竞争,再到数据中心用水问题。但最火的那段,是他回应 AI 能耗批评时说的:「人们总谈训练 AI 模型需要多少能源……但训练人类也需要大量能源,得花 20 年时间,消耗那么多食物,才能变聪明。」

近日,北京大学朱毅鑫教授课题组、北京大学毕彦超教授课题组和山西医科大学第一医院王效春团队通过结合 AI 模型和大脑损伤患者的数据,发现语言其实是一副无形的智能眼镜,时刻在悄悄修饰着我们看到的世界。我们可能以为视觉就是眼睛看到什么就是什么,但是这项成果说明了视觉从来都不是孤立的。事实上,当我们在看图片的时候,其实不只是在看,而是在进行被语言调制过的看。
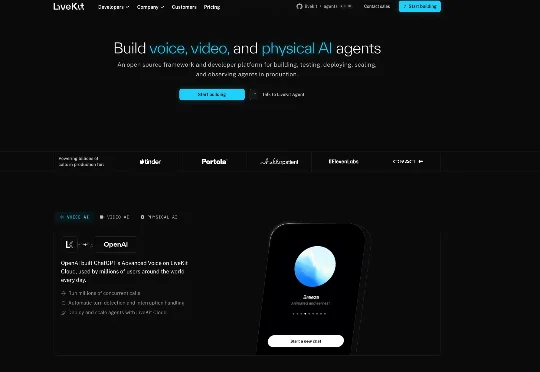
提供软件支撑OpenAI 等公司语音、视频及实体 AI 模型的初创企业 LiveKit,在一轮融资中筹集了 1 亿美元,公司估值达 10 亿美元。LiveKit 的软件和网络运行着利用语音、视频以及所谓物理 AI(应用于机器人技术等任务)的人工智能模型。
路透社最新消息,Meta 新成立的 AI 团队本月已在内部交付了首批关键模型。据悉,该消息来自 Meta 公司的 CTO Andrew Bosworth,他表示该团队的 AI 模型「非常好」(very good)。